Generating Data Science Project Ideas
Written by Adam Green.
Side Projects
Most projects require large teams & expensive software - it's not possible to build a bridge as a lone civil engineer with a laptop and an internet connection. It's different in the world of data science - while extracting large amounts of business value from data science can require a large team, a single data professional is capable of completing a smaller version of what they do in industry on their own.
The data science community is open with data, tools and education - making working on a personal data science portfolio a realistic goal for motivated data professionals.
Work done outside of a company can demonstrating your technical ability and creating content for others to use and learn from. It's also a great way to increase your data science skills for take home tests & professional data science work.
Working on side projects come with a challenge - coming up with an idea. This post outlines a few ways to come up with an idea for your data science project.
Seven Idea Strategies
This post looks at seven strategies for generating data science project ideas - presented in order of increasing difficulty:
- A Kaggle competition,
- Work on a problem you care about,
- Start with an environment and do control,
- Reimplement a machine learning paper,
- Improve existing work with machine learning,
- Curate a dataset,
- Build a tool.
Business Context Challenge
One of the challenges of doing a project outside of a company is a lack of business context.
Business context allows data scientists to make technical decisions. Knowing what the business wants helps a data scientist understand what technical decisions to make.
If the business needs a model that can be interpreted, this narrows the choice of models that a data scientist will consider. If the model needs to run on embedded hardware, deep learning might not be a good option.
A lack of business context means you have choices to make in your project - choices that are usually defined by the business you are working for. It's up to you fill in the gap left by your lack of business context - one way to do this is with your own motivation & goals.
Motivation and Goals
Motivation and goals can be used to fill the business context gap in personal projects.
Instead of making technical decisions with the needs of an employer in mind, you can make technical decisions in the context of your own reasons to do the project. You need to be clear about two things - your motivation and your goals.
Your motivation is about the why - why you want to do a project.
There are a number of reasons why a data scientist will undertake a new project. For those breaking into data science, a project gives a chance to demonstrate their ability and skills. For established data scientists, projects offer the opportunity for learning and continuous improvement, or the chance to contribute to a problem they care about.
Common motivations include:
- building your portfolio,
- demonstrating a specific ability to an employer,
- learning a new language (such as Javascript or Haskell),
- learning a new technique (like computer vision or probabilistic programming),
- learning a new library (learning Tensorflow or PyTorch),
- learning a new tool (such as Docker),
- contributing to solving real world problem,
- contributing to scientific literature,
- earning money by winning a competition.
Be conservative with your motivation - pick only one. While it is possible to work towards multiple motivations at once, it's also possible to get into trouble here. Trying to impress an employer while learning a new language may not end up looking so impressive!
Your goals are about the what - what you want to achieve from the project. A goal is concrete, and should be something you can touch, show or download, such as:
- a successful job application
- a well documented Github repository
- a blog post
- a downloable dataset
- a useable tool
- a Kaggle competition placement
Unlike your motivation, you should have multiple, prioritized goals. For example, if your main goal is a blog post, it's still important to work toward a well documented Github repository.
Don't forget to enjoy your project! Not every moment of your project will be unimaginable bliss (especially if you have to install CUDA) - but there should be moments you enjoy, such as seeing a model learn for the first time, the quality of your code improve, or delight in fixing a bug.
Now that we understand your motivations and goals, we can look at the seven strategies to generate data science project ideas.
1. A Kaggle competition
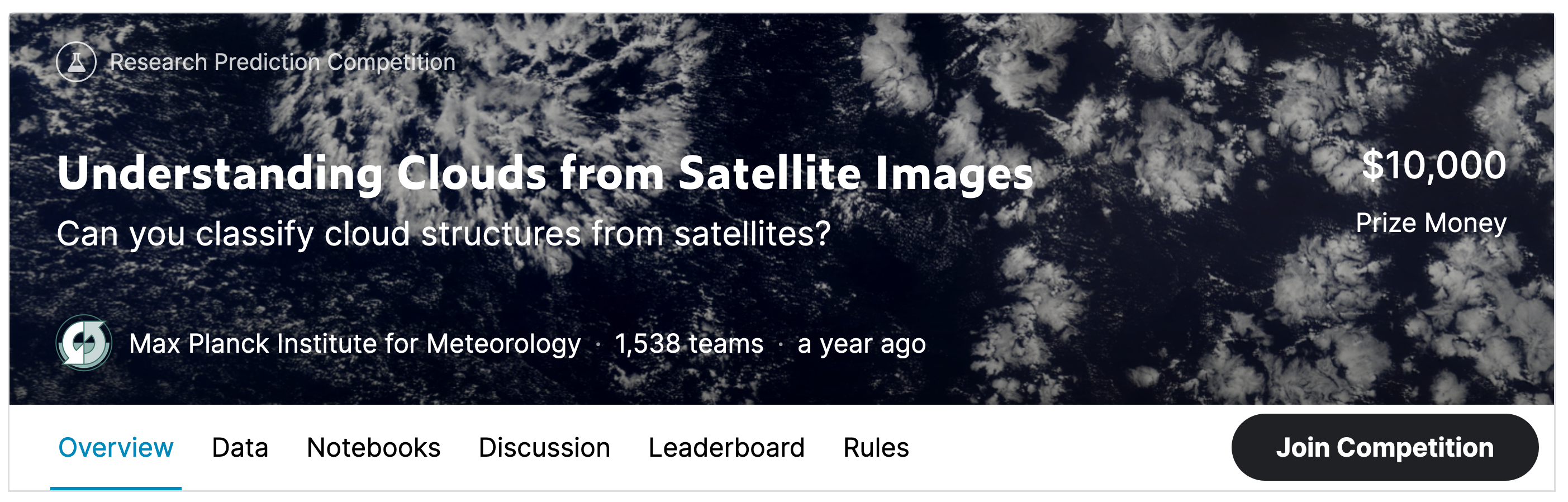
Kaggle is a website that runs data science competitions - companies offer up their business problem and give out cash prizes for the best solutions.
The great thing about a Kaggle competition is that they come with business context.
Competitions usually include all of the following:
- a dataset - usually tabular data, images or text,
- a predefined test set,
- the target - the column to predict, such as image class,
- a metric - to judge performance, such as mean square error,
- notebooks (or kernels) of other people's code,
- a leaderboard to compare performance.
All of these things are useful - this is why a Kaggle competition is an easier project. A typical Kaggle competition has more business context than a data scientist would get in industry! For example, choosing a metric is commonly a choice made by a data scientist, not by the business.
Even though a Kaggle competition comes with business context, this does not mean Kaggle competitions are easy to win. Kaggle competitions are usually won by a combination of clever feature engineering, external data, data leaks and massive ensembles of gradient boosted decision trees (such as XGBoost or LightGBM).
The massive ensembles that dominate Kaggle competitions are not common in industry, with the extra engineering effort to train, maintain and deploy them not worth the incremental performance improvements. They do however make sense in a Kaggle competition, where every 0.01% counts.
Competitions run for a certain period of time and then become inactive. If your motivation is to place highly, you are limited to active competitions. However if your motivation is to learn, you should consider the inactive competitions as well.
The best way to start a Kaggle competition is to build off the work of others. Starting with a well performing public notebook gives you a solid base to work from.
It's also possible to be creative on Kaggle. You could take a different approach with a dataset, or even combine datasets across competitions.
If you are looking for a competition to start from, we recommend the following:
- for complete beginners, the Titanic dataset is a right of passage in data science,
- for those looking for something more advanced, the image segmentation competition Understanding Clouds from Satellite Images is one of our favourites.
2. Work on a problem you care about
The problem with a Kaggle competition is that you have no control over what problems the competitions are working on. If you are on a mission to solve a specific problem, or have domain expertise you want to use, there may not be a suitable competition on Kaggle that aligns with your motivation.
If you have a specific problem you care about, before you even start considering dataset, you need to ask - how can data science help to solve this problem? One of the most common ways data scientist help a business is through prediction - which usually means some form of supervised machine learning.
If your insight doesn’t enable a new action or improve an existing one, it isn’t very valuable
Russell Jurney, Agile Data Science
When considering if supervised learning can solve your problem, you need to answer this question - how would an improved prediction help solve my problem? Another way to phrase this question is to ask what action will be taken after a prediction is make. It's important to think through how the prediction will be used in the real world.
Once you understand how a prediction would drive an action, your next steps are to:
- find a dataset,
- select a target to predict,
- select a metric to judge performance,
- research other peoples solutions to similar problems.
You'll notice that these steps align with what a company provides in a Kaggle competition - this is the missing business context that you need to define.
There are a number of places to find datasets - some popular places are:
- Kaggle Datasets (different from Competitions, often limited to only the dataset (no target or metric)),
- UC Irvine Machine Learning Repository,
- StatLib Datasets Archive.
You can find a larger list of datasets here.
When considering datasets, you should ask:
- how much data do I have? How many rows & columns?
- are the features useful?
- what is the target?
- how is the target distributed - is it imbalanced?
- how much measurement error is there in the target & features?
- was the data sampled with any bias?
- is there a seasonal effect?
Selecting a metric is crucial. In a business, metrics are ideally those that align with the goals of the business. Without this context, the choice of metric should be one that aligns with solving the problem you care about.
3. Start With An Environment And Do Control
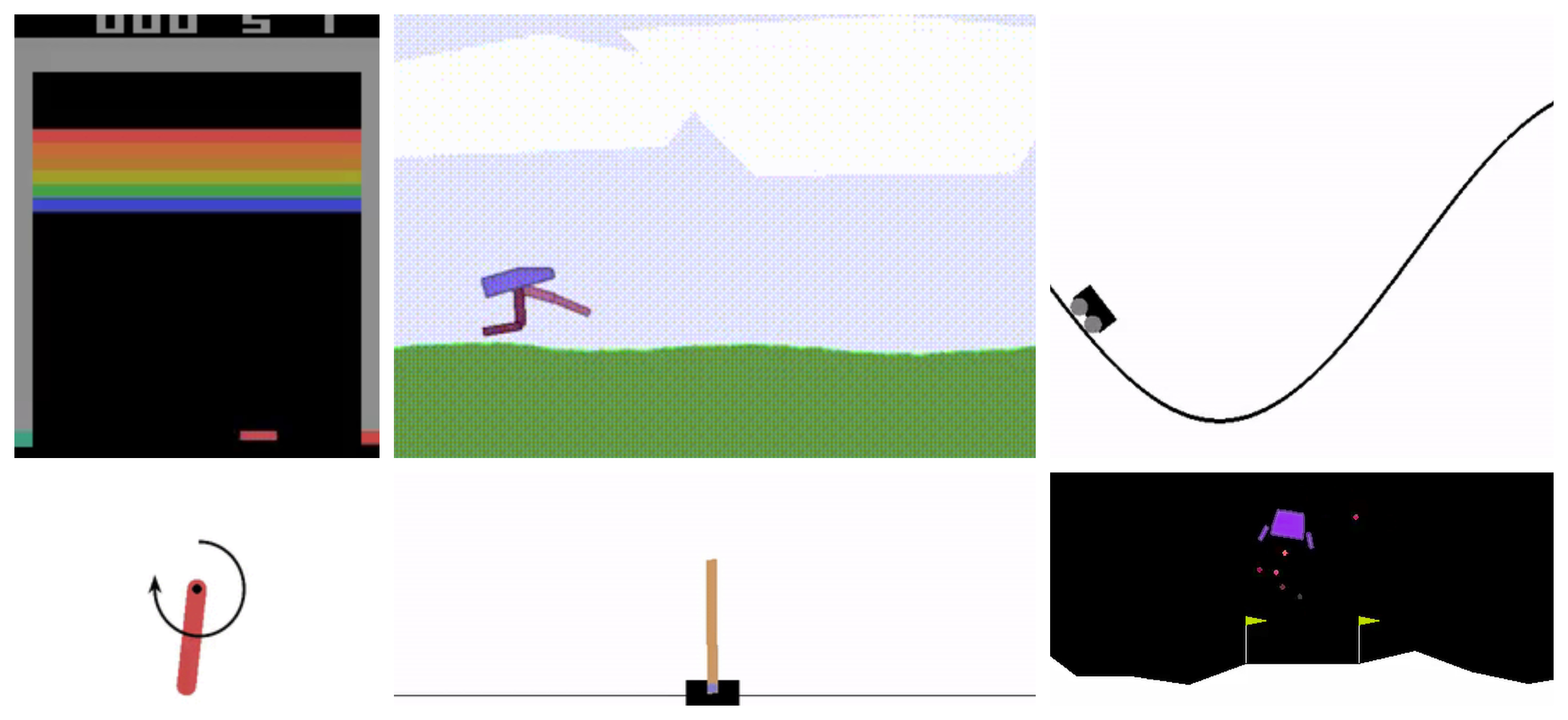
The first two strategies are for supervised learning projects - using some features to predict a target. Control is different - control is about getting a system to behave how you want. Taking a complex system and designing an algorithm to control it is a step up from supervised learning.
A popular family of control algorithms is reinforcement learning (others include optimal control and evolutionary algorithms).
Reinforcement learning can be seen as the intersection of three tasks:
- generating a dataset,
- labelling data,
- fitting functions.
No wonder control is harder than supervised learning, where you are given both data & labels for free!
Two common motivations for doing a control project - one is to learn about a control algorithm through implementing it, the other to control a real system.
Motivation - Learning About A Control Algorithm
If your motivation is to learn about how a specific algorithm works, implementing it is a great start. If you are starting out, we recommend picking a simpler algorithm rather than starting with something complex.
Unfortunately it's not quite as simple as picking older methods - often in control advances are made by simplifying. For example, the more recent PPO is simpler than TRPO.
If you don't know where to start, we recommend the following:
- value function methods - vanilla Q-learning,
- policy gradient methods - REINFORCE with a baseline,
- evolutionary algorithms - 1-Lambda ES.
Once you have picked an algorithm, you need an enviroment to control. When you are developing & debugging, it's important to work with battle tested environment - ideally you are familiar with. This familiarity means you know how quickly an agent should start learning and what good performance looks like. It also means you won't chase your tail debugging your agent when the environment has a bug!
Good environments for debugging and tuning are well tested and cheap to simulate - we recommend the following (both from Open AI's gym):
- CartPole-v1 for discrete action spaces
- Pendulum-v0 for continuous action spaces
Motivation - Controlling a Real Dynamic System
If you are interested in controlling a real dynamic system (real world or simulated), your tasks are different. Some of the questions you need to answer are:
- can I simulate my environment?
- does my observation include enough infomation to make decisions with?
- what is my reward signal?
Not having any of these can be a big problem for learning how to do control. For any control problem, you should start with understanding domain specific solutions before looking at general purpose learning methods. General learning methods are powerful because they generalize to many different problems - specalized solutions work because they are tuned for a single task.
4. Reimplement a Machine Learning Paper
This strategy comes from Andrew Ng's talk Nuts and Bolts of Applying Deep Learning.
Ng's advice to read and replicate machine learning papers is specifically for machine learning researchers - he suggests that this will eventually lead to novel ideas of your own (after around 20-50 papers!).
Even if your goals are not machine learning research, reimplementing papers is one of the best ways to learn machine learning.
A big challenge in data science and machine learning how many different techniques that can be used to solve problems. By reimplementing the work of others, you get a view of what techniques are often used and if they actually work.
An important step with this strategy is accessing the original dataset - this can require engaging with the authors of the paper (and can take a few weeks). Even better if they can also supply any code they used - this can be useful in checking what steps the original authors took. Sometimes important details don't make it into the paper!
You might think that having the code base makes this an easy project - in reality, often research code bases are messy, and include lots of code that researchers used to try out different things that never made it into the paper.
Reimplementing doesn't mean you need to do everything exactly the same as the original codebase. You can structure the codebase differently, use different data or different libraries, such as taking work done in Tensorflow and reimplementing it in Pytorch.
You may also think about extending the paper - doing grid-searches over hyperparameters or trying out different architectures.
The basic process for reimplementing a machine learning paper is:
- get access to the original dataset (or something close)
- review the original paper & code base
- review other reimplementations you can find
- decide on a target level of performance
Don't be afraid to not exactly match the performance of the paper. Researchers often have access to free compute, which may not be true for you! What you want to show is good performance - enough that if you did scale the model, it would match the original work.
5. Improve Existing Work With Machine Learning
The previous strategy is about taking existing machine learning work and reimplementing it. This strategy is about taking existing work and applying new techniques - using machine learning in place of domain specific methods, or modern machine learning (such a deep learning) in place of classical machine learning methods.
It's not a simple as taking a machine learning paper and improving it through hyperparameter tuning - here we are talking about doing something the authors of the original paper never considered.
The steps for this strategy are similar to reimplementing a machine learning paper:
- get access to the original dataset (or something close)
- review the original work (ideally an academic paper & code base)
- review potential novel improvements to the original work
- experiment with improvements
Even though the authors will report the performance of their solution in the paper, you will want to reimplement their solution as your baseline. This is to both to be able to compare it to your improvements, and to reproduce their results. Don't rely on comparing your results to theirs as printed.
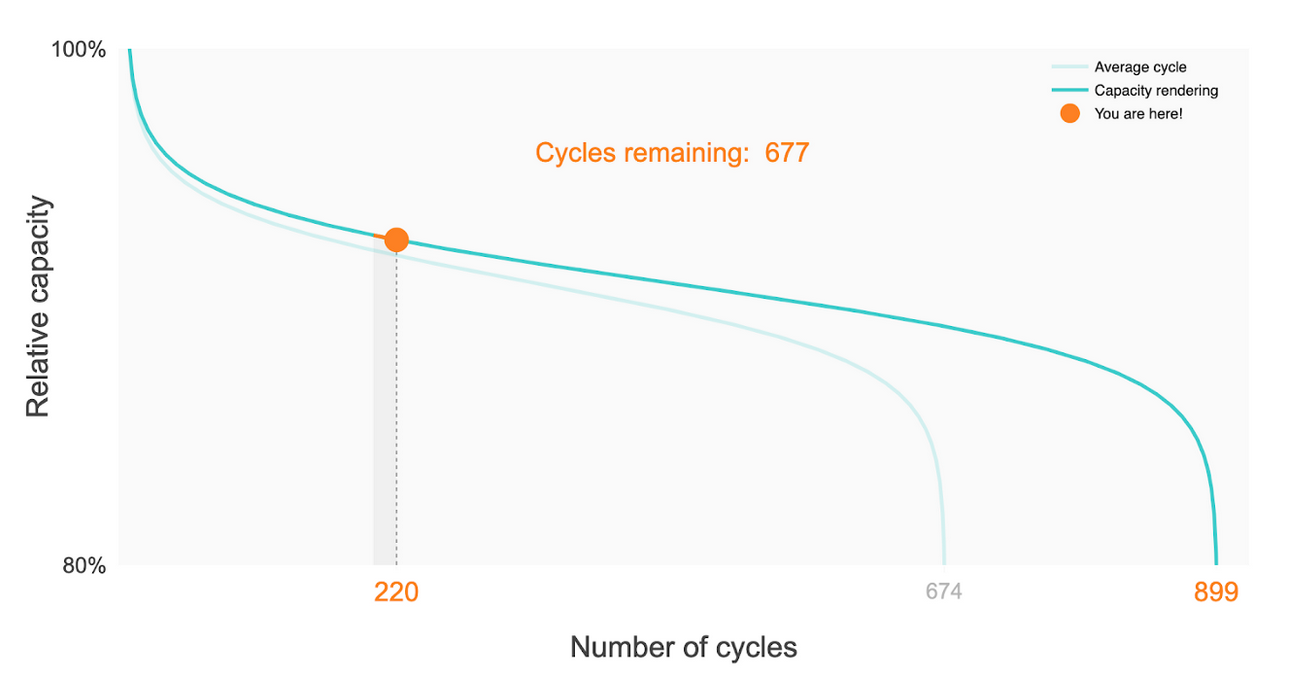
An excellent example of this is work done improving the forecasting of battery lifetime, where Hannes Knobloch, Adem Frenk, and Wendy Chang applied deep learning to the problem of prediciting how many cycles a battery will last for. They also have an excellent Github repository - well worth checking out.
6. Curate a Dataset

Progress in machine learning is driven by datasets & benchmarks. It's no coincidence that MNIST and ImageNet occurred concurrently with progress in computer vision. These datasets serve as benchmarks for researchers to compare improvements to algorithms and models, and the ability to easily access them in frameworks like Scikit-Learn or TensorFlow makes working with them effortless.
Contributing a dataset is one of the noblest things a researcher can do. It's also challenging, as you need to think about all the messyness that comes with the real world of data:
- where to get it
- how to store it (CSV, JSON, SQLite)
- how to share it (S3)
- how noisy are the labels
- how biased is the sampling
- is the dataset stationary - if not, how will you update it
A key question with dataset curation is where to get the raw data from. It's likely you will use some form of web scraping here. You'll also probably need some domain knowledge to know where the raw data lives, and how it would be useful to solve a problem.
Another interesting question is how much data cleaning to do. Basic data cleaning such as converting datetimes it ISO 8601 will be appreciated - but filling in missing values may introduce noise that researchers would want to deal with themselves. Best practice is to include both the raw data and clean data, so your users can make their own decisions.
7. Build a Tool
Tools shape research directions - Yann LeCun
The most challenging of all our strategies is to build a tool. Why is building a tool hard? Improving a tool requires feedback from users - people actually have to use it for you to understand if it's solving their problem.
Another challenge is the additional skills required, such as providing a REST API, a command line tool or a Python package - skills that are usually not core in a traditional data science workflow. These skills are however valuable in data science - even if you only use them to improve your own workflow, you won't regret learning them.
The benefits of building tools are many. Along with expanding your software engineering skillset, they also allow you to better understand frameworks and libraries you use.
Contributing to Existing Open Source Packages
If you are interested in your work making an impact, building a tool from scratch is unlikely to be the best option. It's more likely that contributing to an open-source tool is more useful to the world. These contributions can range from adding documentation, writing tests, fixing bugs, refactoring or adding new features.
Contributing to an existing open source tool is a fantastic way to give back. It's also an excellent way to learn about how these tools work under the hood. Finally, it can look great on your CV.
You'll also improve your own code. Reading other people's code gives you a chance to explore features of languages you haven't used before, and see different coding styles. Take a look at the excellent Read Code for more about the benefits of reading code.
The question then becomes - what tool should you contribute too? Here we suggest contrubiting to one of your dependencies. Use pandas a lot? Go check out the Issues on their Github and see what they need done.
Building a Tool from Scratch
While contributing to existing open source tools is the best way to do work that is useful, this doesn't mean you should never write your own tools from scratch. Building your own tool is great for learning, as you get to touch every part of the project.
Just because it's unlikely you will build the new Keras, this doesn't mean you shouldn't build your own deep learning library. Building tools have a number of benefits beyond being widely used.
Working on someone else's tools means you won't get to design the project from the start - meaning you won't get to implement the interface or the core logic of the program.
If you plan to build a project from scratch, first start out by reviewing the source code for similar projects. Be opinionated - copy what you like, change what you don't.
Summary
Key takeaways from this blog post are:
- side projects are a realistic goal for data professionals, that help improve & demonstrate skills,
- side projects require defining business context and understanding your motivation & goals.
The seven strategies for coming up with a data science project idea are:
- A Kaggle competition,
- Work on a problem you care about,
- Start with an environment and do control,
- Reimplement a machine learning paper,
- Improve existing work with machine learning,
- Curate a dataset,
- Build a tool.
Thanks for reading!
If you enjoyed this blog post, make sure to check out our free 77 data science lessons across 22 courses.